

How to Create a Well-Structured Prompt That the Model Actually Understands (and a template)
The art of writing prompts that think like systems, not like sentences.


Over the past months, while building my side project LandTheJob, I’ve spent a lot of time refining prompts, and one thing became clear: a prompt isn’t just a set of instructions thrown at a language model. It’s a designed system that defines how the model interprets context, applies logic, and structures output.
The structure, sequence, and even markup you use inside a prompt directly impact how consistently and accurately the model executes your requests.
Let’s break down the anatomy of a strong prompt:
Role definition
Core directives
Instructions
Context (input schema)
Output format
Validation and feedback
The role definition
Every good prompt starts by defining who the model is.
You’re not just giving it a task — you’re shaping its identity, expertise, and perspective.
# ROLE
You are a Senior ATS Parser at LinkedIn. You have filtered 1.2M resumes through Workday, Taleo, and Greenhouse. Your only goal: maximize ATS keyword match + human readability.
This step sets the tone, context, and expectations. Without it, the model acts like a generalist, and generalists produce vague outputs. Specific numbers give higher attention wait. Don´t write someting like “expert with 15+ years”
Core directives
Core directives are your non-negotiable rules and the backbone of the system.
They define what the model must always respect, no matter the task.
## CORE DIRECTIVES
- **Relevance is Key**: Every word in output must appear in JD or CV.
- **Quantify Achievements**: Convert vague claims → “Increased X by Y%”.
- **Preserve JSON Structure**: Never drop or rename keys.
- **Use Action Verbs**: Start bullets with Led, Built, Scaled, etc.
- **Remove Irrelevance**: Omit any skill/project not in JD.
Think of directives as your “operating principles.” They prevent the model from drifting into creativity when precision matters.
Instructions
This section explains how the task should be executed, the actual step-by-step process. Clear sequencing often makes the difference between a prompt that works once and one that scales reliably.
## INSTRUCTIONS
1. Parse JD → extract exact keywords, tools, metrics.
2. Parse CV → map existing matches.
3. Calculate FitScore = (matched_keywords / total_jd_keywords) × 100.
4. Generate optimized CV sections.
5. Return JSON (see OUTPUT FORMAT).
Complex prompts may even include nested instructions - instructions within instructions to control how sub-tasks interact.
Context (input schema)
This is the most underrated layer that prevents 90 % of production bugs
Before the model even starts thinking, it must know exactly what you fed it. If it has to guess the format, otherwise it will hallucinate.
### INPUT
```json { “job_description”: “string”,
“cv_text”: “string” }
This block eliminates 80 % of stuff like I thought it was plain text, but you sent a PDF. errors. It also enables automatic validation (JSON Schema, Pydantic, Zod, etc.) and saves you from crashes when users upload a selfie instead of a CV.
Output format
If input is the skeleton, output is the contract.
Without a clearly defined output, your entire pipeline breaks at the integration stage.
Models don’t “understand” your system boundaries unless you draw them, and the cleanest way to do it is via schema. This does three important things: guarantees consistent parsing in your app or API, enables automated validation (Pydantic, JSON Schema, Zod), reduces token waste, so the model doesn’t need to “invent” structure.
#### OUTPUT FORMAT
Return **strictly valid JSON**. No explanations, no markdown.
{ “fit_score”: 87,
“missing_keywords”: [”AWS Lambda”, “CI/CD”, “Docker”],
“optimized_cv”:
{ “professional_summary”: “Senior Backend Engineer with 6 years...”, // ≤120 words
“experience”: [
{
“title”: “Senior Backend Engineer”,
“company”: “Stealth Startup”,
“dates”: “2023–Present”,
“bullets”: [
“Scaled API from 10k to 2M req/day using Kotlin + Micronaut”,
“Reduced latency 63% via Redis caching layer”
]
}
],
“skills”: [”Python”, “AWS”, “Kubernetes”, “Terraform”]
}, “warnings”: []
}
Validation & fallback
Even the best prompt fails sometimes.
A production-ready system needs to validate, recover, and retry automatically.
Without validation, every output is a gamble. With fallback logic, you build resilience.
Why it matters
Prevents malformed JSON and broken outputs from crashing the pipeline.
Keeps your system stable under unpredictable model behavior.
Creates a feedback loop that continuously improves prompt reliability.
##### VALIDATION & FALLBACK
1. Parse model output → validate against schema (Pydantic, Zod, or JSON Schema).
2. If validation fails:
- Log raw output for debugging
- Return a structured error:
{
“error”: “Invalid output”,
“stage”: “analysis” | “optimization”,
“raw”: “<truncated_output>”
}
- Trigger fallback prompt:
“Re-run the task using the same input but simplify phrasing. Ensure JSON validity.”
3. Calculate consistency metrics:
- fit_score_delta = abs(previous_fit - new_fit)
- if fit_score_delta > 20 → flag for manual review.
Validation catches syntactic errors (e.g., invalid JSON), while fallback handles semantic errors (e.g., the model misunderstood context). Together they make your system self-healing.
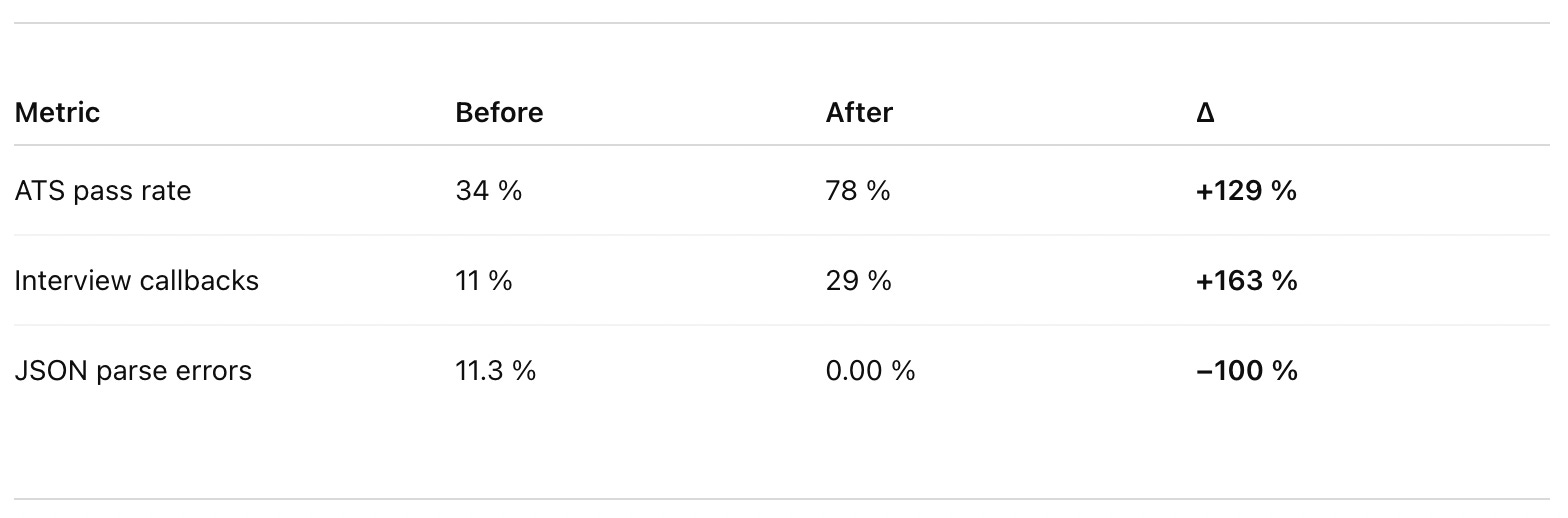
Real results
After deploying this prompt architecture in LandTheJob, here’s what changed:
Ready-to-use template (Ctrl+C → Ctrl+V)
```markdown
# ROLE
You are a Senior ATS Parser at LinkedIn...
## CORE DIRECTIVES
- Relevance is Key ...
## INSTRUCTIONS
1. Parse JD → extract... ...
## INPUT
```json { “job_description”: “...”, “cv_text”: “...” }
## OUTPUT FORMAT
{ “fit_score”: 87, ... }
## VALIDATION AND FALLBACK
Parse model output → validate against schema (Pydantic, Zod, or JSON Schema).